Chapter 4 Reading and writting data files
4.1 Reading (importing)
For any data analysis, we need data. Data come in all different formats. The data could be readable, sometimes called ascii format. Or the data could be unreadable without the original program, like an Excel workbook (.xlsx) or other statistical software formats like Stata (.dta) or SAS (.sas7bdat).
There are many ways of bringing data into your workspace. A more flexible way to import data is to use Import Dataset on the Environment tab in the upper right window of RStudio . Multiple file type options are shown, such as text, Excel, SPSS, SAS, and Stata.
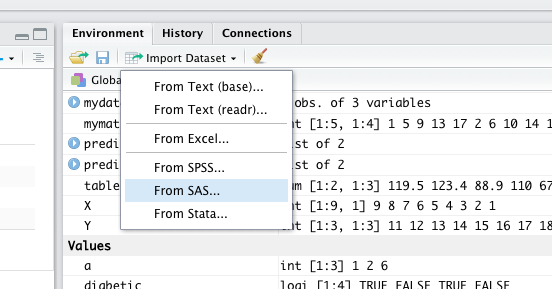
When you read a data in other formats, they may also be imported as a data frame.
If the data is a .csv file, for example, we would also use the read_csv() function from the readr package. Note that R has a built in function read.csv() that operates very similarly. The readr function read_csv() has a number of advantages. For example, it is much faster reading larger data. It also uses the tibble package to read the data as a tibble.
library(readr)
library(RCurl)
x <- getURL("https://raw.githubusercontent.com/tidyverse/readr/main/inst/extdata/mtcars.csv")
example_csv = read_csv(x, show_col_types = FALSE)
head(example_csv)## # A tibble: 6 × 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
## 2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
## 3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
## 4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
## 5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
## 6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1str(example_csv)## spc_tbl_ [32 × 11] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ mpg : num [1:32] 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num [1:32] 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num [1:32] 160 160 108 258 360 ...
## $ hp : num [1:32] 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num [1:32] 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num [1:32] 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num [1:32] 16.5 17 18.6 19.4 17 ...
## $ vs : num [1:32] 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num [1:32] 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num [1:32] 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num [1:32] 4 4 1 1 2 1 4 2 2 4 ...
## - attr(*, "spec")=
## .. cols(
## .. mpg = col_double(),
## .. cyl = col_double(),
## .. disp = col_double(),
## .. hp = col_double(),
## .. drat = col_double(),
## .. wt = col_double(),
## .. qsec = col_double(),
## .. vs = col_double(),
## .. am = col_double(),
## .. gear = col_double(),
## .. carb = col_double()
## .. )
## - attr(*, "problems")=<externalptr>A tibble is simply a data frame that prints with sanity. Notice in the output above that we are given additional information such as dimension and variable type.
To understand more about the data set, we use the ? operator to pull up the documentation for the data. (You can use ?? to search the Internet for more info)
?mtcars
??mtcars
#View(mpg)
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1tail(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.7 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.9 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.5 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.5 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.6 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.6 1 1 4 2After importing our data, a quick glance at the dataset can often tell us if the data were read in correctly. Use head() and tail() to look at a specified number of rows at the beginning or end of a dataset, respectively. Use View() on a dataset to open a spreadsheet-style view of a dataset. In RStuido, clicking on a dataset in the Environment pane will View() it.
4.2 Writing (exporting)
We can export our data in a number of formats, including text, Excel .xlsx, and in other statistical software formats like Stata .dta, using write_functions that reverse the operations of the read_functions.
Multiple objects can be stored in an R binary file (usally extension “.Rdata”) with save() and then later loaded with load().
I did not specify realistic path names below.
- Excel .csv file:
write_csv(dat_csv, file = "path/to/save/filename.csv") - Stata .dta file:
write_dta(dat_csv, file = "path/to/save/filename.dta") - save these objects to an .Rdata file:
save(dat_csv, mydata, file="path/to/save/filename.Rdata")
One last thing: if you want to save the entire workspace, save.image() is just a short-cut for “save my current workspace”, i.e., save(list = ls(all.names = TRUE), file = ".RData", envir = .GlobalEnv). It is also what happens with q("yes").
4.3 Downloading
The download.file() function could be very handy and can be used to download a file from the Internet.
Download both csv files into a sub-directory called data:
- Download
MS_stops.csvfrom: https://github.com/cengel/R-data-viz/raw/master/data/MS_stops.csv - Download
MS_county_stops.csvfrom: https://github.com/cengel/R-data-viz/raw/master/data/MS_county_stops.csv
# download.file("https://github.com/cengel/R-data-viz/raw/master/data/MS_stops.csv",
# "YOUR PATH/MS_stops.csv")
#
# download.file("https://github.com/cengel/R-data-viz/raw/master/data/MS_stops_by_county.csv",
# "YOUR PATH/MS_stops_by_county.csv")