Chapter 29 Factor Analysis
Factor Analysis (FA) is a method for modeling observed variables, and their covariance structure, in terms of a smaller number of underlying latent (unobserved) “factors”. In FA the observed variables are modeled as linear functions of the “factors.” In PCA, we create new variables that are linear combinations of the observed variables. In both PCA and FA, the dimension of the data is reduced.
A factor model can be thought of as a series of multiple regressions, predicting each of the observable variables \(X_{i}\) from the values of the (unobservable) common factors \(f_{i}\):
\[ \begin{gathered} X_{1}=\mu_{1}+l_{11} f_{1}+l_{12} f_{2}+\cdots+l_{1 m} f_{m}+\epsilon_{1} \\ X_{2}=\mu_{2}+l_{21} f_{1}+l_{22} f_{2}+\cdots+l_{2 m} f_{m}+\epsilon_{2} \\ \vdots \\ X_{p}=\mu_{p}+l_{p 1} f_{1}+l_{p 2} f_{2}+\cdots+l_{p m} f_{m}+\epsilon_{p} \end{gathered} \]
where \(\mu_{i}\) is the variable mean (intercept).
The regression coefficients \(l_{i j}\) (the partial slopes) for all of these multiple regressions are called factor loadings: \(l_{i j}=\) is loading of the \(i^{t h}\) variable on the \(j^{t h}\) factor. With a matrix notation, we can show the matrix of factor loadings:
\[ \mathbf{L}=\left(\begin{array}{cccc} l_{11} & l_{12} & \ldots & l_{1 m} \\ l_{21} & l_{22} & \ldots & l_{2 m} \\ \vdots & \vdots & & \vdots \\ l_{p 1} & l_{p 2} & \ldots & l_{p m} \end{array}\right) \]
The errors \(\varepsilon_{i}\) are called the specific factors. Here, \(\varepsilon_{i}=\) specific factor for variable \(i\). When we collect them in a vector, we can express these series of multivariate regression as follows:
\[\begin{equation} \mathbf{X}=\boldsymbol{\mu}+\mathbf{L f}+\boldsymbol{\epsilon} \tag{29.1} \end{equation}\]
There are multiple assumptions:
- \(E\left(\epsilon_{i}\right)=0\) and \(\operatorname{var}\left(\epsilon_{i}\right)=\psi_{i}\) (a.k.a “specific variance”),
- \(E\left(f_{i}\right)=0\) and \(\operatorname{var}\left(f_{i}\right)=1\),
- \(\operatorname{cov}\left(f_{i}, f_{j}\right)=0\) for \(i \neq j\),
- \(\operatorname{cov}\left(\epsilon_{i}, \epsilon_{j}\right)=0\) for \(i \neq j\),
- \(\operatorname{cov}\left(\epsilon_{i}, f_{j}\right)=0\),
Hence,
- \(\operatorname{var}\left(X_{i}\right)=\sigma_{i}^{2}=\sum_{j=1}^{m} l_{i j}^{2}+\psi_{i}\). The term \(\sum_{j=1}^{m} l_{i j}^{2}\) is called the Communality for variable \(i\). The larger the communality, the better the model performance for the \(i\) th variable.
- \(\operatorname{cov}\left(X_{i}, X_{j}\right)=\sigma_{i j}=\sum_{k=1}^{m} l_{i k} l_{j k}\),
- \(\operatorname{cov}\left(X_{i}, f_{j}\right)=l_{i j}\)
The factor model for our variance-covariance matrix can then be expressed as:
\[\begin{equation} \Sigma=\mathbf{L L}^{\prime}+\mathbf{\Psi} \tag{29.2} \end{equation}\]
where,
\[ \boldsymbol{\Psi}=\left(\begin{array}{cccc} \psi_{1} & 0 & \ldots & 0 \\ 0 & \psi_{2} & \ldots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \ldots & \psi_{p} \end{array}\right) \] And,
\[ \hat{l}_{i j}=\hat{e}_{j i} \sqrt{\hat{\lambda}_j} \]
The total variance of each variable given in the factor model (27.2) can be explained by the sum of the shared variance with another variable, \(\mathbf{L} \mathbf{L}^{\prime}\) (the common variance or communality) and the unique variance, \(\mathbf{\Psi}\), inherent to each variable (specific variance)
There are multiple methods to estimate the parameters of a factor model. In general, two methods are most common: PCA and MLE. Let’s have an example. The data set is called bfi and comes from the psych package. It is made up of 25 self-report personality items from the International Personality Item Pool, gender, education level and age for 2800 subjects and used in the Synthetic Aperture Personality Assessment: The personality items are split into 5 categories: Agreeableness (A), Conscientiousness (C), Extraversion (E), Neuroticism (N), Openness (O). Each item was answered on a six point scale: 1 Very Inaccurate, 2 Moderately Inaccurate, 3 Slightly Inaccurate, 4 Slightly Accurate, 5 Moderately Accurate, 6 Very Accurate.
library(psych)
library(GPArotation)
data("bfi")
describe(bfi)## vars n mean sd median trimmed mad min max range skew
## A1 1 2784 2.41 1.41 2 2.23 1.48 1 6 5 0.83
## A2 2 2773 4.80 1.17 5 4.98 1.48 1 6 5 -1.12
## A3 3 2774 4.60 1.30 5 4.79 1.48 1 6 5 -1.00
## A4 4 2781 4.70 1.48 5 4.93 1.48 1 6 5 -1.03
## A5 5 2784 4.56 1.26 5 4.71 1.48 1 6 5 -0.85
## C1 6 2779 4.50 1.24 5 4.64 1.48 1 6 5 -0.85
## C2 7 2776 4.37 1.32 5 4.50 1.48 1 6 5 -0.74
## C3 8 2780 4.30 1.29 5 4.42 1.48 1 6 5 -0.69
## C4 9 2774 2.55 1.38 2 2.41 1.48 1 6 5 0.60
## C5 10 2784 3.30 1.63 3 3.25 1.48 1 6 5 0.07
## E1 11 2777 2.97 1.63 3 2.86 1.48 1 6 5 0.37
## E2 12 2784 3.14 1.61 3 3.06 1.48 1 6 5 0.22
## E3 13 2775 4.00 1.35 4 4.07 1.48 1 6 5 -0.47
## E4 14 2791 4.42 1.46 5 4.59 1.48 1 6 5 -0.82
## E5 15 2779 4.42 1.33 5 4.56 1.48 1 6 5 -0.78
## N1 16 2778 2.93 1.57 3 2.82 1.48 1 6 5 0.37
## N2 17 2779 3.51 1.53 4 3.51 1.48 1 6 5 -0.08
## N3 18 2789 3.22 1.60 3 3.16 1.48 1 6 5 0.15
## N4 19 2764 3.19 1.57 3 3.12 1.48 1 6 5 0.20
## N5 20 2771 2.97 1.62 3 2.85 1.48 1 6 5 0.37
## O1 21 2778 4.82 1.13 5 4.96 1.48 1 6 5 -0.90
## O2 22 2800 2.71 1.57 2 2.56 1.48 1 6 5 0.59
## O3 23 2772 4.44 1.22 5 4.56 1.48 1 6 5 -0.77
## O4 24 2786 4.89 1.22 5 5.10 1.48 1 6 5 -1.22
## O5 25 2780 2.49 1.33 2 2.34 1.48 1 6 5 0.74
## gender 26 2800 1.67 0.47 2 1.71 0.00 1 2 1 -0.73
## education 27 2577 3.19 1.11 3 3.22 1.48 1 5 4 -0.05
## age 28 2800 28.78 11.13 26 27.43 10.38 3 86 83 1.02
## kurtosis se
## A1 -0.31 0.03
## A2 1.05 0.02
## A3 0.44 0.02
## A4 0.04 0.03
## A5 0.16 0.02
## C1 0.30 0.02
## C2 -0.14 0.03
## C3 -0.13 0.02
## C4 -0.62 0.03
## C5 -1.22 0.03
## E1 -1.09 0.03
## E2 -1.15 0.03
## E3 -0.47 0.03
## E4 -0.30 0.03
## E5 -0.09 0.03
## N1 -1.01 0.03
## N2 -1.05 0.03
## N3 -1.18 0.03
## N4 -1.09 0.03
## N5 -1.06 0.03
## O1 0.43 0.02
## O2 -0.81 0.03
## O3 0.30 0.02
## O4 1.08 0.02
## O5 -0.24 0.03
## gender -1.47 0.01
## education -0.32 0.02
## age 0.56 0.21To get rid of missing observations and the last three variables,
df <- bfi[complete.cases(bfi[,1:25]),1:25]
dim(bfi[,1:25])## [1] 2800 25dim(df)## [1] 2436 25The first decision that we need make is the number of factors that we will need to extract. For \(p=28\), the variance-covariance matrix \(\Sigma\) contains \[ \frac{p(p+1)}{2}=\frac{25 \times 26}{2}=325 \] unique elements or entries. With \(m\) factors, the number of parameters in the factor model would be
\[ p(m+1)=25(m+1) \]
Taking \(m=5\), we have 150 parameters in the factor model. How do we choose \(m\)? Although it is common to look at the results of the principal components analysis, often in social sciences, the underlying theory within the field of study indicates how many factors to expect.
scree(df)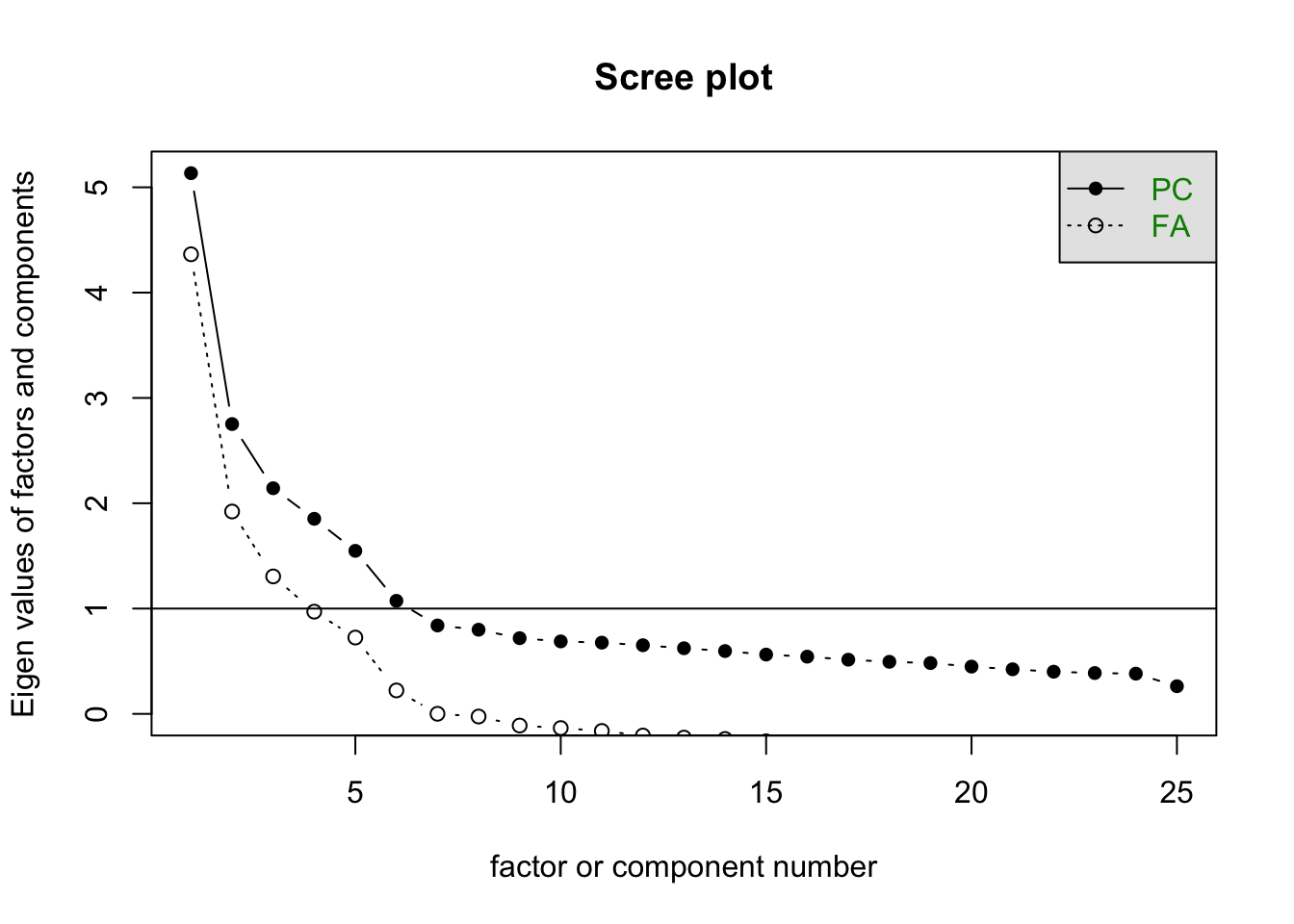
Let’s use the factanal() function of the build-in stats package
pa.out <- factanal(df, factors = 5)
pa.out##
## Call:
## factanal(x = df, factors = 5)
##
## Uniquenesses:
## A1 A2 A3 A4 A5 C1 C2 C3 C4 C5 E1 E2 E3
## 0.830 0.576 0.466 0.691 0.512 0.660 0.569 0.677 0.510 0.557 0.634 0.454 0.558
## E4 E5 N1 N2 N3 N4 N5 O1 O2 O3 O4 O5
## 0.468 0.592 0.271 0.337 0.478 0.507 0.664 0.675 0.744 0.518 0.752 0.726
##
## Loadings:
## Factor1 Factor2 Factor3 Factor4 Factor5
## A1 0.104 -0.393
## A2 0.191 0.144 0.601
## A3 0.280 0.110 0.662
## A4 0.181 0.234 0.454 -0.109
## A5 -0.124 0.351 0.580
## C1 0.533 0.221
## C2 0.624 0.127 0.140
## C3 0.554 0.122
## C4 0.218 -0.653
## C5 0.272 -0.190 -0.573
## E1 -0.587 -0.120
## E2 0.233 -0.674 -0.106 -0.151
## E3 0.490 0.315 0.313
## E4 -0.121 0.613 0.363
## E5 0.491 0.310 0.120 0.234
## N1 0.816 -0.214
## N2 0.787 -0.202
## N3 0.714
## N4 0.562 -0.367 -0.192
## N5 0.518 -0.187 0.106 -0.137
## O1 0.182 0.103 0.524
## O2 0.163 -0.113 0.102 -0.454
## O3 0.276 0.153 0.614
## O4 0.207 -0.220 0.144 0.368
## O5 -0.512
##
## Factor1 Factor2 Factor3 Factor4 Factor5
## SS loadings 2.687 2.320 2.034 1.978 1.557
## Proportion Var 0.107 0.093 0.081 0.079 0.062
## Cumulative Var 0.107 0.200 0.282 0.361 0.423
##
## Test of the hypothesis that 5 factors are sufficient.
## The chi square statistic is 1490.59 on 185 degrees of freedom.
## The p-value is 1.22e-202The first chunk provides the “uniqueness” (specific variance) for each variable, which range from 0 to 1 . The uniqueness, sometimes referred to as noise, corresponds to the proportion of variability, which can not be explained by a linear combination of the factors. This is the \(\hat{\Psi}\) in the equation above. A high uniqueness for a variable indicates that the factors do not account well for its variance.
The next section reports the loadings ranging from \(-1\) to \(1.\) This is the \(\hat{\mathbf{L}}\) in the equation (27.2) above. The loadings are the contribution of each original variable to the factor. Variables with a high loading are well explained by the factor. Notice there is no entry for certain variables since \(R\) does not print loadings less than \(0.1\).
The communalities for the \(i^{t h}\) variable are computed by taking the sum of the squared loadings for that variable. This is expressed below:
\[ \hat{h}_i^2=\sum_{j=1}^m \hat{l}_{i j}^2 \]
This proportion of the variability is denoted as communality. Another way to calculate the communality is to subtract the uniquenesses from 1. An appropriate factor model results in low values for uniqueness and high values for communality.
apply(pa.out$loadings^2,1,sum) # communality## A1 A2 A3 A4 A5 C1 C2 C3
## 0.1703640 0.4237506 0.5337657 0.3088959 0.4881042 0.3401202 0.4313729 0.3227542
## C4 C5 E1 E2 E3 E4 E5 N1
## 0.4900773 0.4427531 0.3659303 0.5459794 0.4422484 0.5319941 0.4079732 0.7294156
## N2 N3 N4 N5 O1 O2 O3 O4
## 0.6630751 0.5222584 0.4932099 0.3356293 0.3253527 0.2558864 0.4815981 0.2484000
## O5
## 0.27405961 - apply(pa.out$loadings^2,1,sum) # uniqueness## A1 A2 A3 A4 A5 C1 C2 C3
## 0.8296360 0.5762494 0.4662343 0.6911041 0.5118958 0.6598798 0.5686271 0.6772458
## C4 C5 E1 E2 E3 E4 E5 N1
## 0.5099227 0.5572469 0.6340697 0.4540206 0.5577516 0.4680059 0.5920268 0.2705844
## N2 N3 N4 N5 O1 O2 O3 O4
## 0.3369249 0.4777416 0.5067901 0.6643707 0.6746473 0.7441136 0.5184019 0.7516000
## O5
## 0.7259404The table under the loadings reports the proportion of variance explained by each factor. The row Cumulative Var gives the cumulative proportion of variance explained. These numbers range from 0 to 1; Proportion Var shows the proportion of variance explained by each factor, and the row SS loadings gives the sum of squared loadings. This is sometimes used to determine the value of a particular factor. A factor is worth keeping if the SS loading is greater than 1 (Kaiser’s rule).
The last section of the output reports a significance test: The null hypothesis is that the number of factors in the model is sufficient to capture the full dimensionality of the data set. Conventionally, we reject \(H_0\) if the \(p\)-value is less than \(0.05\). Such a result indicates that the number of factors is too low. The low \(p\)-value in our example above leads us to reject the \(H_0\), and indicates that we fitted NOT an appropriate model.
Finally, with our estimated factor model, we may calculate \(\hat{\Sigma}\) and compare it to the observed correlation matrix, \(S\), by simple matrix algebra.
Lambda <- pa.out$loadings
Psi <- diag(pa.out$uniquenesses)
S <- pa.out$correlation
Sigma <- Lambda %*% t(Lambda) + Psi
round(head(S) - head(Sigma), 2)## A1 A2 A3 A4 A5 C1 C2 C3 C4 C5 E1 E2
## A1 0.00 -0.12 -0.03 0.01 0.04 0.05 0.06 0.03 0.09 0.00 0.08 0.03
## A2 -0.12 0.00 0.03 0.02 -0.03 -0.04 -0.05 0.03 -0.03 0.02 -0.04 -0.01
## A3 -0.03 0.03 0.00 0.02 0.02 -0.02 -0.02 -0.02 -0.01 -0.01 0.03 0.01
## A4 0.01 0.02 0.02 0.00 -0.02 -0.04 0.04 -0.06 0.01 -0.04 0.01 0.01
## A5 0.04 -0.03 0.02 -0.02 0.00 0.02 -0.01 0.01 0.00 0.00 0.03 0.03
## C1 0.05 -0.04 -0.02 -0.04 0.02 0.00 0.07 0.01 0.01 0.05 0.01 0.01
## E3 E4 E5 N1 N2 N3 N4 N5 O1 O2 O3 O4
## A1 0.07 0.05 0.01 -0.01 -0.02 0.02 0.01 0.00 0.06 0.06 0.02 -0.02
## A2 -0.06 -0.04 0.07 0.00 0.04 -0.03 -0.01 -0.01 -0.01 -0.01 -0.03 0.01
## A3 0.01 -0.03 -0.01 0.02 0.01 -0.01 -0.02 -0.05 0.00 -0.02 0.00 -0.03
## A4 -0.01 0.01 -0.02 0.02 -0.02 0.01 -0.02 0.00 0.02 -0.02 0.00 -0.02
## A5 0.03 0.04 -0.01 0.00 0.00 -0.01 -0.01 0.00 0.00 0.00 0.00 0.00
## C1 -0.02 0.06 0.02 -0.02 -0.01 0.02 0.01 0.01 -0.01 0.02 0.00 0.04
## O5
## A1 0.07
## A2 -0.05
## A3 -0.01
## A4 -0.01
## A5 0.00
## C1 0.02This matrix is also called as the residual matrix.
For more see: https://cran.r-project.org/web/packages/factoextra/readme/README.html