Chapter 34 Random Forest
We will utilize embedding for direct forecasting with Random Forests. We choose the random forests algorithm because it does not need an explicit tuning by a grid search. In the practice, however, we can still search for the number of trees and the number of variables randomly sampled as candidates at each split.
Let’s get our COVID-19 data:
library(tsibble)
library(fpp3)
load("~/Dropbox/ToolShed_draft/toronto2.rds")
day <- seq.Date(from = as.Date("2020/03/01"),
to = as.Date("2020/11/21"), by = 1)
tdata <- tibble(Day = day, data[,-1])
toronto2 <- tdata %>%
as_tsibble(index = Day)
toronto2## # A tsibble: 266 x 8 [1D]
## Day cases mob delay male age temp hum
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2020-03-01 4 -0.0172 36.8 0.75 55 -4.2 65.5
## 2 2020-03-02 6 -0.0320 8.5 1 45 3.8 84
## 3 2020-03-03 10 -0.0119 15 0.7 54 2.3 90
## 4 2020-03-04 7 0.0186 25.7 0.286 50 3.35 71
## 5 2020-03-05 7 0.0223 21 0.429 48.6 1.2 63.5
## 6 2020-03-06 10 -0.00626 13.1 0.5 36 0.04 75
## 7 2020-03-07 8 0.0261 10.4 0.5 46.2 -1.65 54
## 8 2020-03-08 10 0.0273 11.6 0.9 50 6.3 56
## 9 2020-03-09 18 -0.0158 8.89 0.611 35.6 12.5 55
## 10 2020-03-10 29 -0.0521 9.69 0.448 41.7 5.15 79
## # … with 256 more rowsAs before, the data contain the first wave and the initial part of the second wave in Toronto for 2020. It is from Ontario Data Catalogue sorted by episode dates (Day), which is the date when the first symptoms were started. The mobility data is from Facebook, all_day_bing_tiles_visited_relative_change, which is reflects positive or negative change in movement relative to baseline. The other variables related to tests are delay, which is the time between test results and the episode date, the gender distribution of people is given by male, age shows the average age among tested people any given day. The last two variables, temp and hum, show the daily maximum day temperature and the average outdoor humidity during the day, respectively.
Except for age all other variables are non-stationary. We will take their first difference and make the series stationary before we proceed.
df <- toronto2 %>%
mutate(dcases = difference(cases),
dmob = difference(mob),
ddelay = difference(delay),
dmale = difference(male),
dtemp = difference(temp),
dhum = difference(hum))
dft <- df[ ,-c(2:5,7,8)] #removing levels
dft <- dft[-1, c(1,3:7,2)] # reordering the columnsLet’s first use a univariate setting for a single-window forecasting, which is the last 7 days.
34.1 Univariate
We will not have a grid search on the random forest algorithm, which could be added to the following script:
library(randomForest)
h = 7
w <- 3:21 # a grid for window size
fh <- matrix(0, length(w), h)
rownames(fh) <- w
colnames(fh) <- 1:h
for(s in 1:length(w)){
dt <- as.data.frame(embed(as.matrix(dft[ ,2]), w[s]))
test_ind = nrow(dt) - (h)
train <- dt[1:test_ind, ]
test <- dt[-c(1:test_ind), ]
y <- train[ ,1]
X <- train[ ,-1]
for (i in 1:h) {
fit <- randomForest(X, y)
fh[s, ] <- predict(fit, test[ ,-1])
y <- y[-1]
X <- X[-nrow(X), ]
}
}
fh## 1 2 3 4 5 6 7
## 3 -15.6018667 9.310533 18.92736 -5.61587 -2.6795667 15.9516667 0.2260143
## 4 -12.3719667 -4.529133 23.81357 -3.81461 -2.9320000 -0.2525905 1.8392667
## 5 -1.4742333 -6.483667 31.81397 -9.31990 -0.6973667 -8.5956000 13.7102333
## 6 3.8286000 -8.144833 26.24103 -14.16233 16.6709762 -14.3093333 14.8530667
## 7 -3.0172667 -15.031933 30.65857 -16.22097 15.5310000 -20.2173000 16.6649333
## 8 5.2647667 -22.161567 48.84670 -9.24960 18.5284667 -13.7705667 31.1602333
## 9 -2.5698667 -33.595100 64.06383 -20.11073 12.9286667 -24.3064333 19.4022667
## 10 -0.7961333 -34.066567 66.01647 -25.87520 12.4119667 -22.4946000 15.1037667
## 11 -0.3373000 -30.130567 63.44670 -24.55370 19.5859000 -18.5808000 14.5011000
## 12 1.4619667 -27.653533 58.79900 -24.95300 16.7328667 -18.0486000 15.0114000
## 13 -2.9238000 -33.887733 51.65223 -25.82973 12.8003333 -15.4098000 14.5947333
## 14 -6.8802333 -27.548500 50.84693 -24.94523 19.0224333 -10.8544000 11.1885667
## 15 -6.5682667 -34.851000 53.98443 -21.68400 17.7346000 -8.3577667 12.5701333
## 16 -10.4813667 -34.439533 62.83657 -25.25887 12.1292667 -13.6516333 12.4343000
## 17 -8.9321667 -33.134067 56.80640 -24.92087 12.5466667 -14.9191000 12.4445667
## 18 -8.2691667 -34.987133 59.46013 -24.90433 16.3243333 -12.7073333 13.6343667
## 19 -6.7537000 -33.219967 60.23873 -25.06637 14.8604000 -11.8669333 8.5879333
## 20 -9.2979333 -30.226100 56.98660 -27.19037 12.8234333 -13.0873000 13.6051000
## 21 -14.7773333 -30.927133 53.32693 -21.27113 8.1717333 -13.3213667 12.8889333We can now see RMSPE for each row (window size):
actual <- test[, 1]
rmspe <- c()
for (i in 1:nrow(fh)) {
rmspe[i] <- sqrt(mean((fh[i, ] - actual)^2))
}
rmspe## [1] 42.85926 43.50368 44.60629 43.76183 44.48864 53.33789 52.58021 51.50009
## [9] 50.84351 49.47312 49.26641 47.78848 50.87072 50.85334 49.53083 50.93861
## [17] 49.90584 48.83803 49.04289which.min(rmspe)## [1] 1And, if we plot several series of our forecast with different window sizes:
plot(actual, type = "l", col = "red",
ylim = c(-80, 50),
ylab = "Actual (red) vs. Forecasts",
xlab = "Last 7 days",
main = "7-Day Foerecasts",
lwd = 3)
lines(fh[1, ], type = "l", col = "blue")
lines(fh[2, ], type = "l", col = "green")
lines(fh[5, ], type = "l", col = "orange")
lines(fh[12, ], type = "l", col = "black")
legend("bottomright",
title = "Lags",
legend = c("3-day", "4-day", "7-day", "14-day"),
col = c("blue", "green", "orange"),
lty = c(1, 1, 1, 1, 1), bty = "o", cex = 0.75)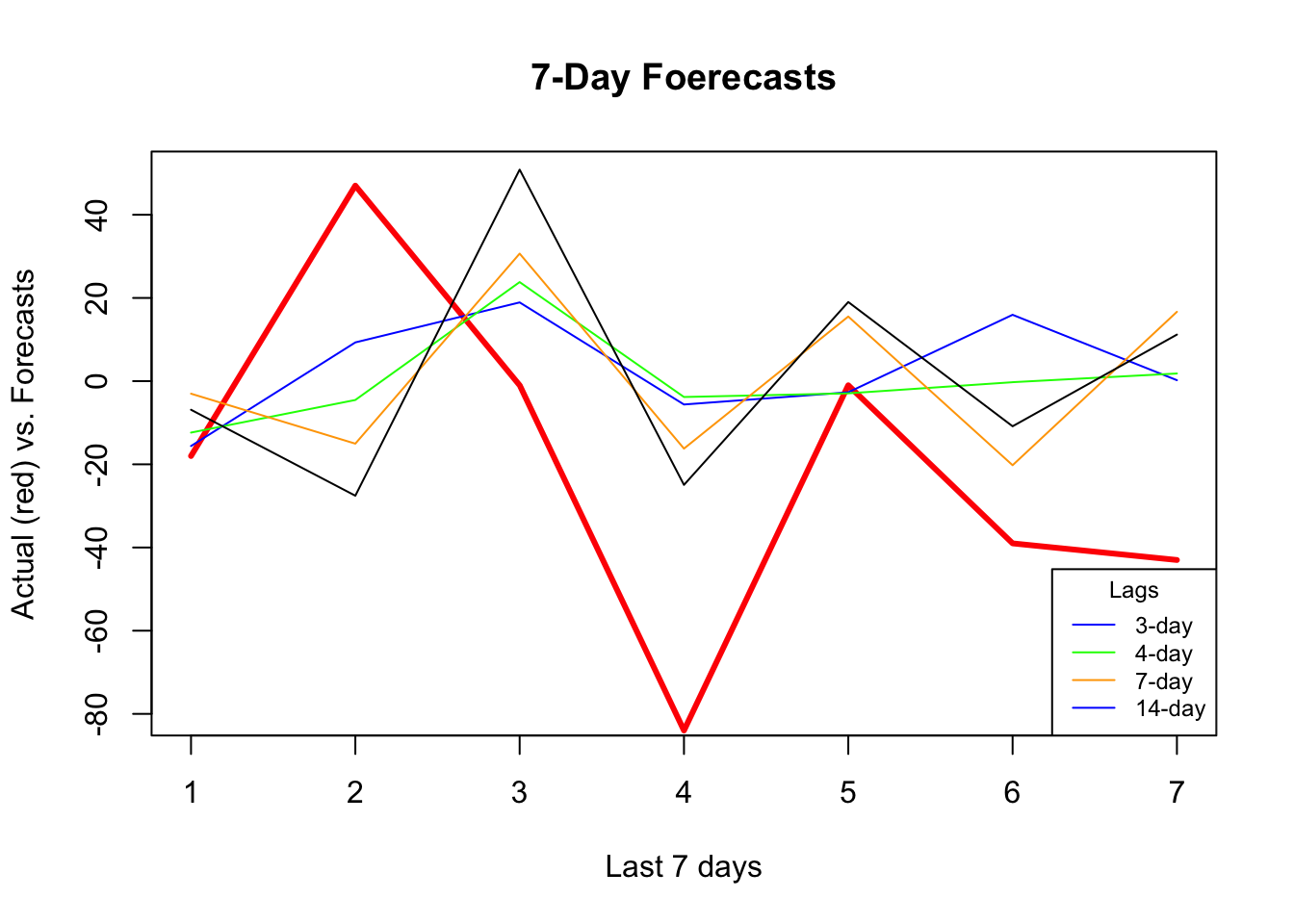
It seems that, as the window size gets larger, the forecast becomes increasingly smooth, perhaps missing the short term dynamics. Another observation is that, although “blue” (3-day window) has the minimum RMSPE, it is not able to capture ups and downs relative to 7-day or 14-day windows.
34.2 Multivariate
Can we increase the prediction accuracy with additional predictors?
library(randomForest)
h = 7
w <- 3:14 # a grid for window size
fh <- matrix(0, length(w), h)
rownames(fh) <- w
colnames(fh) <- 1:h
for(s in 1:length(w)){
dt <- as.data.frame(embed(as.matrix(dft[ ,-1]), w[s]))
test_ind = nrow(dt) - (h)
train <- dt[1:test_ind, ]
test <- dt[-c(1:test_ind), ]
y <- train[ ,1]
X <- train[ ,-1]
for (i in 1:h) {
fit <- randomForest(X, y)
fh[s, ] <- predict(fit, test[ ,-1])
y <- y[-1]
X <- X[-nrow(X), ]
}
}
fh## 1 2 3 4 5 6 7
## 3 -19.212967 -0.5505667 13.49437 -9.00870 -17.5430667 6.925400 -4.2557000
## 4 -22.851400 -0.7982000 11.42873 -8.38390 -16.2173333 3.426533 -3.5931000
## 5 -14.228267 2.0529667 14.70600 -14.20783 -10.5935667 -5.964533 -0.8730333
## 6 -10.960800 2.8480000 22.65230 -13.27867 0.3809333 -9.108467 3.3669667
## 7 -10.663867 -4.8168000 18.97303 -20.47287 5.5657333 -16.195233 9.3020000
## 8 -8.278100 -12.4320000 25.17917 -14.01913 5.2211667 -13.180233 14.9986667
## 9 -13.780500 -22.2859333 51.56193 -24.58650 8.3307000 -20.668067 11.3830000
## 10 -9.698233 -20.9478333 49.88590 -25.36183 6.6301667 -23.558800 12.9146000
## 11 -10.099367 -18.3942667 45.29037 -25.49347 13.1071667 -20.088600 11.6200333
## 12 -9.935000 -18.5712000 49.58857 -25.05527 11.3463667 -22.090933 8.5771000
## 13 -5.606400 -18.5219000 42.03743 -23.81273 10.8609333 -18.827400 8.2242667
## 14 -12.606200 -19.3608333 41.46637 -22.73203 12.2638667 -17.815367 4.9454000actual <- test[,1]
rmspe <- c()
for (i in 1:nrow(fh)) {
rmspe[i] <- sqrt(mean((fh[i,]-actual)^2))
}
rmspe## [1] 41.36984 40.99643 38.00403 38.92336 38.67831 43.55384 45.49992 44.93921
## [9] 43.82537 43.91039 43.24843 42.95095which.min(rmspe)## [1] 3plot(actual, type = "l", col = "red",
ylim = c(-80, +50),
ylab = "Actual (red) vs. Forecasts",
xlab = "Last 7 days",
main = "7-Day Foerecasts",
lwd = 3)
lines(fh[1, ], type = "l", col = "blue")
lines(fh[3, ], type = "l", col = "green")
lines(fh[5, ], type = "l", col = "orange")
lines(fh[12, ], type = "l", col = "black")
legend("bottomright",
title = "Lags",
legend = c("3-day", "5-day", "7-day", "14-day"),
col = c("blue", "green", "orange", "black"),
lty = c(1, 1, 1, 1, 1), bty = "o", cex = 0.75)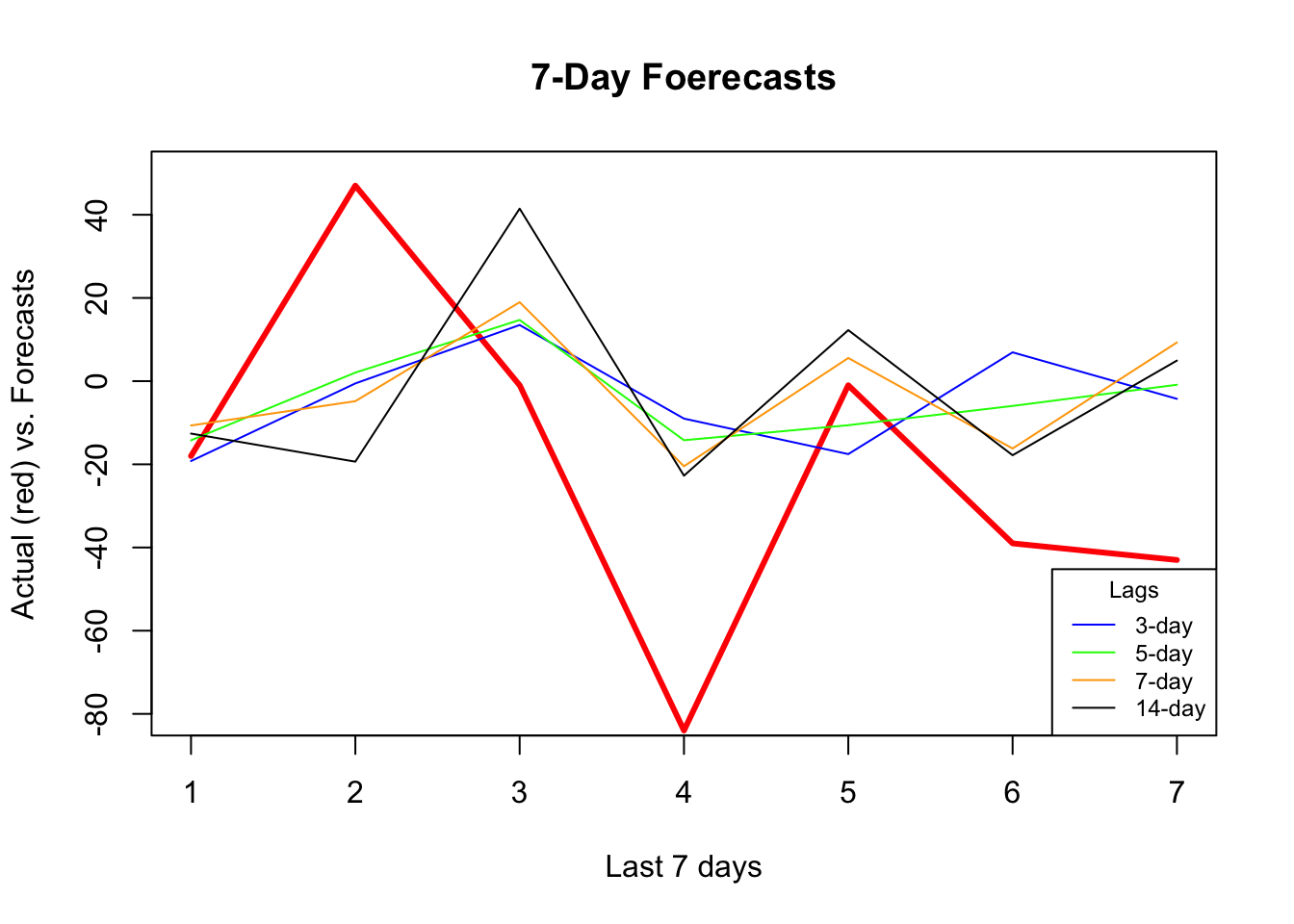
It seems that additional predictors do increase the accuracy. Again, relative to the best model (5-day window) our 7-day window correctly captures most ups and downs in the forecast. Now, a visual inspection shows that all RMSPE’s are lower than the univariate forecasts. We would tend to conclude that this is because of the new predictors, specially mobility, temperature, and humidity. But, the COVID-19 data have many well-known issues related to measurement inaccuracies. As a side note, we need to test if those differences are statistical significant or not (i.e. Diebold-Mariano Test).
34.3 Rolling and expanding windows
A seven-day window is not enough for a reliable judgment on the forecast accuracy. One way to deal with this issue is to use rolling or expanding windows to predict the next h days. The following example shows a 1-day-ahead forecast with varying lags for embedding.
library(randomForest)
l = 3:10 # lags for embedding
ws = 150 # size of each rolling window
rmspe <- c()
all_fh <- vector(mode = "list", length = length(l))
all_y <- vector(mode = "list", length = length(l))
for(s in 1:length(l)) {
dt <- as.data.frame(embed(as.matrix(dft[, -1]), l[s]))
nwin <- nrow(dt) - ws #number of windows
fh <- c()
y <- c()
for(i in 1:nwin){
train <- dt[i:(ws + i - 1), ] # each loop, window moves one day forward
test <- dt[(ws + i), ]
set.seed(i+s)
fit <- randomForest(train[, -1], train[, 1])
fh[i] <- predict(fit, test[, -1])
y[i] <- test[, 1] # to use later for plotting
}
all_y[[s]] <- y
all_fh[[s]] <- fh
err <- test[, 1] - fh
rmspe[s] <- sqrt(mean(err^2))
}
rmspe## [1] 45.17990 44.74564 45.36820 45.07520 45.89481 46.96887 46.98404 46.80637bst <- which.min(rmspe)
l[bst] # Winning lag in embedding## [1] 4To change the application above to an expanding-window forecast, we just need to change dt[i:(ws + i - 1), ] to dt[1:(ws + i - 1), ] in the script. Now, we can plot the results:
par(mfrow=c(1,2))
plot(all_y[[bst]], type = "l", col="red",
ylab = "Actual (red) vs Predicted (Blue)",
xlab = "Days",
main = "1-Day-Ahead")
lines(all_fh[[bst]], col="blue")
plot(all_y[[bst]][60:110], type = "o", col="red",
ylab = "Actual (red) vs Predicted (Blue)",
xlab = "Days",
main = "Last 50 Days")
lines(all_fh[[bst]][60:110], col="blue")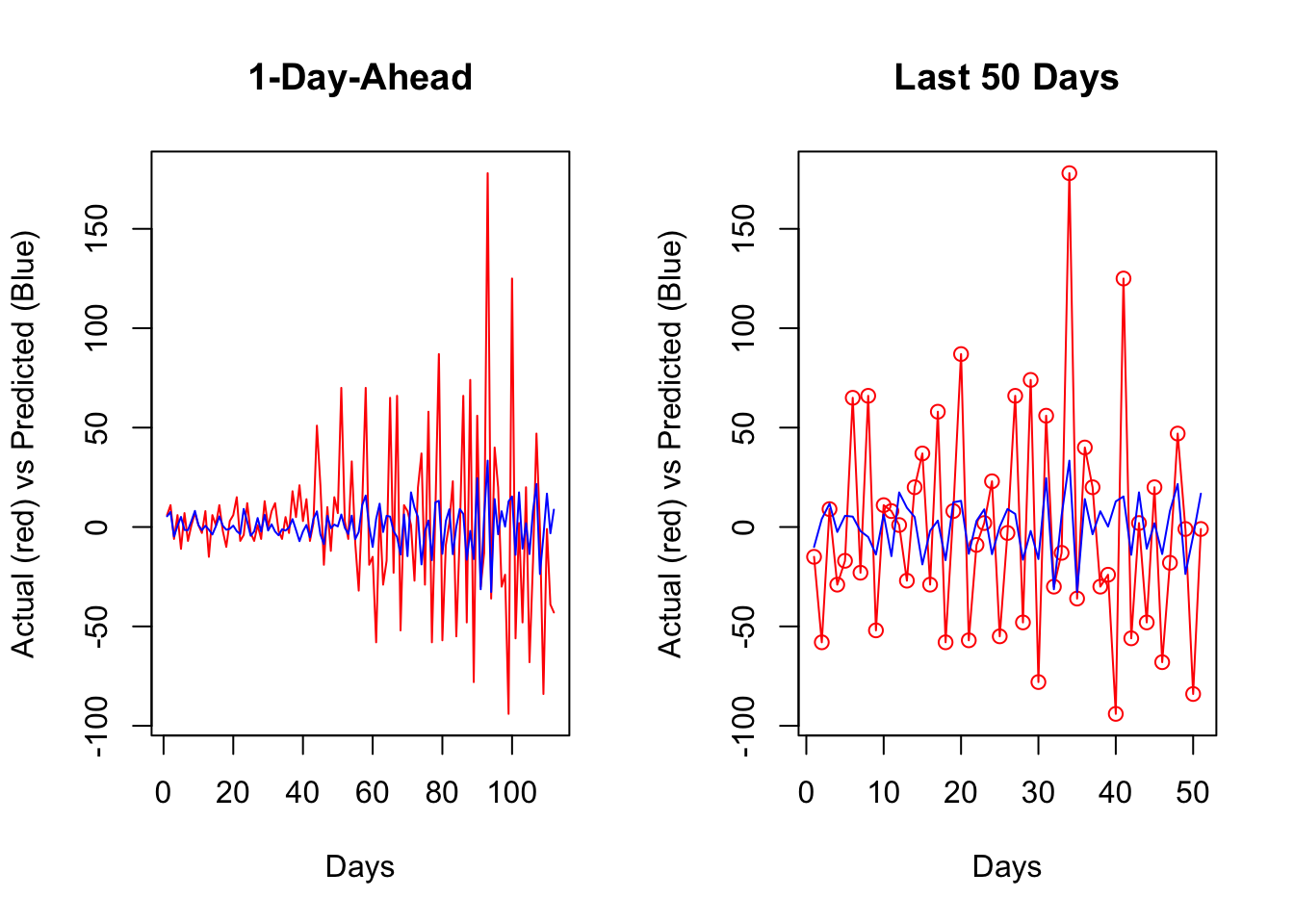
Getting the predicted values back to originals can be achieved by:
\[ \begin{aligned} & y_{t+1}=y_t+z_{t+1} \\ & y_{t+2}=y_{t+1}+z_{t+2}=y_t+z_{t+1}+z_{t+2} \end{aligned} \]
set.seed(321)
y <- rnorm(10)
z <- diff(y) # first differences
back <- cumsum(c(y[1], z))
cbind(y, back)## y back
## [1,] 1.7049032 1.7049032
## [2,] -0.7120386 -0.7120386
## [3,] -0.2779849 -0.2779849
## [4,] -0.1196490 -0.1196490
## [5,] -0.1239606 -0.1239606
## [6,] 0.2681838 0.2681838
## [7,] 0.7268415 0.7268415
## [8,] 0.2331354 0.2331354
## [9,] 0.3391139 0.3391139
## [10,] -0.5519147 -0.5519147Since our algorithm predict the changes in observations, a simple sum would do the job for back transformation. For example, as a starting point, our algorithm predicts the change in \(Y\) from day 156 to 157 (window size 150 plus the best lag window, 6). When we add this predicted change to the actual \(Y\) at 156, it will give us the back-transformed forecast at day 157.
y <- df$cases
# The first forecast is at ws (150) + l[best] (6) + 1, which is 157
# The first actual Y should start a day earlier
# removing all Y's until ws+l[bst]
y_a_day_before <- y[-c(1:(ws+l[bst]-1))]
# This adds predicted changes to observed values a day earlier
back_forecast <- head(y_a_day_before, -1) + all_fh[[bst]]
# Actual Y's in the test set starting at ws (150) + l[best] (6) + 1, which is 157
ytest <- y[-c(1:(ws+l[bst]))]
plot(ytest, type = "l", col = "blue",
ylab = "Actual Y (Blue) vs Forecast (Red)",
xlab = "Days",
main = "Back-transformed Forecast"
)
lines(back_forecast, type = "l", col = "red")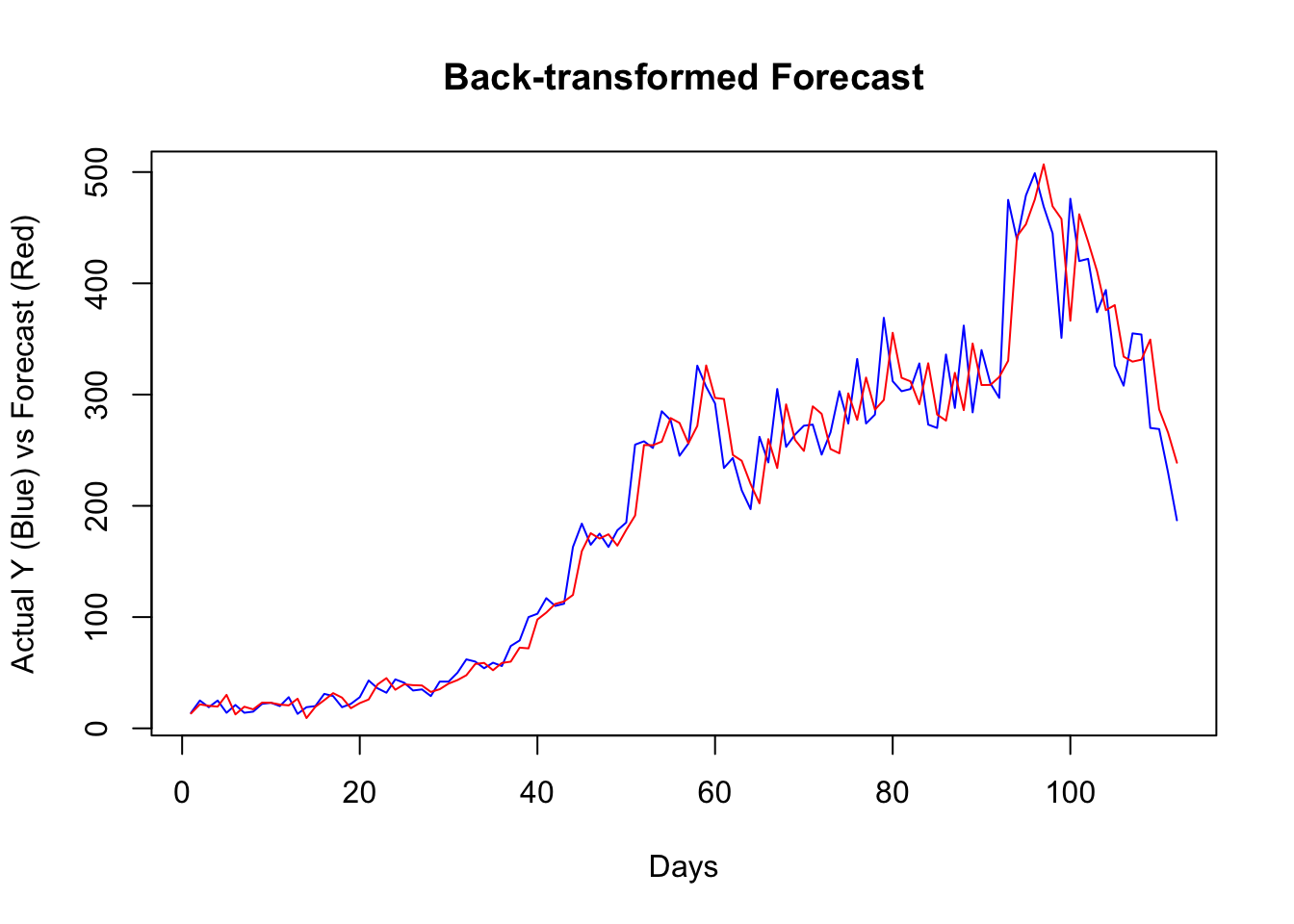
It seems that, for most days, our algorithm simply forecasts the next day by using the value from a day before. If we change our algorithm to a 7-day-ahead forecast, this would be different. This is also a common problem when the predictive model has a poor forecasting power. Again, this is not due to our algorithm, but forecasting an epi curve with imperfect test data is almost impossible job, as we highlighted earlier.
In practice, however, there are several ways that we can improve the scripts above. For example, we can consider the (rolling or expanding) window size as a hyperparameter. We can also have an explicit training for the Random Forest algorithm. We can have an ensemble forecasting by adding other predictive algorithms to the script, like boosting. Further, we can develop a base forecast that would give us a benchmark to see how much our algorithm improves against that base. Moreover, we could apply a transformation to the data in order to stabilize the variance in all variables.